前回までは、ロジスティック回帰とニューラルネットワークを題材に、機械学習のアルゴリズムの開発を経験しました。機械学習のアルゴリズムの開発は、高校・大学で学んだ微積分、線形代数、確率、情報理論およびプログラム言語を駆使して、以下のような手順で行われています。
1)モデルの設計:ソフトマックス線形モデル、階層モデルなど
2)損失関数の設計:交差エントロピーなど
3)学習データの構造の設計:行列、ベクトル表現など
4)学習データを用いた損失関数の(近似)最小解の導出:勾配など
5)最小解のプログラム言語で実装:Pythonなど
参考書
本ブログの内容の詳細は、「機械学習スタートアップシリーズ ゼロからつくるPython機械学習プログラミング入門」に掲載されています。
機械学習に必要な数学の復習から、機械学習のアルゴリズムの導出およびPythonの基本ライブラリのみを用いた実装方法まで学びたい方は、本書籍をご活用ください。
bookclub.kodansha.co.jp
さて、今回からは、機械学習のアルゴリズムを利用する経験をしていきます。まず、前回実装したニューラルネットワークを、文章分類よび画像の分類に応用する例を紹介します。その後、これら2つの例を参考に各自でニューラルネットワークを自分たちで設定した課題に応用していきます。
【Pythonによる機械学習4(ニューラルネット応用 1/4)の目次】
感情分類とは
文章分類の題材として、Amazonの商品レビューの内容が肯定的(Positive)か、否定的(Negative)かを分類する感情分類の課題を考えます。このような文章分類が精度よく実現できると、ツイッターやブログなどでつぶやかれた製品や有名人に関する文章を収集して、製品のユーザやテレビの視聴者による評価を自動的に分析できるようになります。例えば、Yahoo! Japanのリアルタイム検索では、感情分析の機能が提供されています。以下は、2017年12月5日時点で、話題となっている有名人「上沼恵美子」と「とろサーモン」をリアルタイム検索した例です。
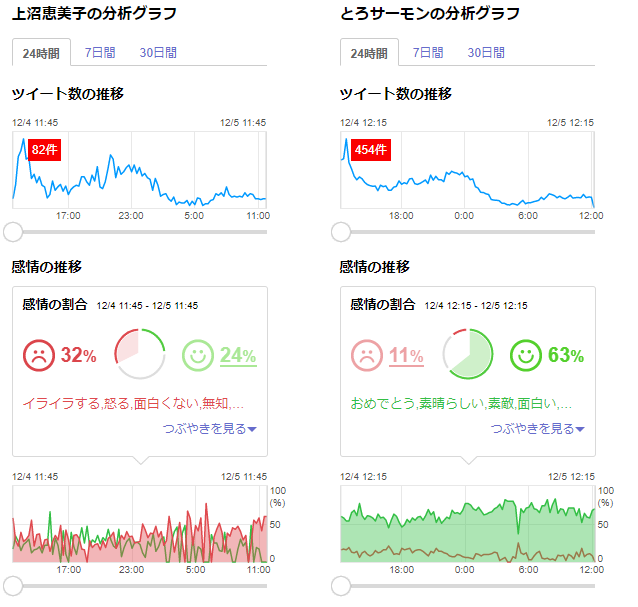
感情の割合が対照的なのがわかります。
データの準備
このような感情分析を実現するために、今回は、sentiment_labelled_sentencesフォルダ下のamazon_cells_labelled.txtを用います。本データは、Pythonによる機械学習1(Pythonの基礎 4/4) - 八谷大岳の覚え書きブログでも扱いましたが、以下のように商品レビュー文章「sentence」と、肯定的か否かの感情カテゴリ「score」の列から構成されます。ここで、「score=1」が肯定的なレビュー、「sentence=0」が否定的なレビューに対応しています。
sentence score 0 So there is no way for me to plug it in here i... 0 1 Good case, Excellent value. 1 2 Great for the jawbone. 1 3 Tied to charger for conversations lasting more... 0 4 The mic is great. 1 5 I have to jiggle the plug to get it to line up... 0 ... 994 Kind of flops around. 0 995 The screen does get smudged easily because it ... 0 996 What a piece of junk.. I lose more calls on th... 0 997 Item Does Not Match Picture. 0 998 The only thing that disappoint me is the infra... 0 999 You can not answer calls with the unit, never ... 0
この1000件の商品レビューのうちランダムに選択した800件を学習データとして用いて、商品レビュー「sentence」から感情カテゴリ「score」を予測するニューラルネットワークを学習し、残りの200件で評価を行っていきます。
次に、data.pyのsentimentalLabelledSentencesを用いて、学習データと評価データを用意していきます。Pythonをインタラクティブモードで起動し、sentimentalLabelledSentencesの機能を見ていきます。
>>> import data # amazon_cells_labelled.txtを指定してsentimentalLabelledSentencesクラスのインスタンス化myData >>> myData = data.sentimentalLabelledSentences('amazon_cells_labelled.txt') # index=0のsentence(文章)の取り出し >>> sentence = myData.data['sentence'][0] >>> sentence 'So there is no way for me to plug it in here in the US unless I go by a converter.' # 文章を単語に分解 >>> words = myData.sentence2words(sentence) >>> words ['so', 'there', 'is', 'no', 'way', 'for', 'me', 'to', 'plug', 'it', 'in', 'here', 'in', 'the', 'us', 'unless', 'i', 'go', 'by', 'a', 'converter']
sentence2wordsを用いて、文章を単語に分解することができることがわかります。さらに、連続するN個の単語を繋げて一つの塊として扱うN-gramは、wordNgram(N, 単語リスト)メソッドにより抽出することができます。
# uni-gram (1-gram)の抽出 >>> myData.wordNgram(1,words) ['so', 'there', 'is', 'no', 'way', 'for', 'me', 'to', 'plug', 'it', 'in', 'here', 'in', 'the', 'us', 'unless', 'i', 'go', 'by', 'a', 'converter'] # bi-gram (2-gram)の抽出 >>> myData.wordNgram(2,words) ['so-there', 'there-is', 'is-no', 'no-way', 'way-for', 'for-me', 'me-to', 'to-plug', 'plug-it', 'it-in', 'in-here', 'here-in', 'in-the', 'the-us', 'us-unless', 'unless-i', 'i-go', 'go-by', 'by-a', 'a-converter', 'converter'] # tri-gram (3-gram)の抽出 >>> myData.wordNgram(3,words) ['so-there-is', 'there-is-no', 'is-no-way', 'no-way-for', 'way-for-me', 'for-me-to', 'me-to-plug', 'to-plug-it', 'plug-it-in', 'it-in-here', 'in-here-in', 'here-in-the', 'in-the-us', 'the-us-unless', 'us-unless-i', 'unless-i-go', 'i-go-by', 'go-by-a', 'by-a-converter', 'a-converter', 'converter']
N-gramは、N=1のときはuni-gram、N=2のときはbi-gram、N=3のときはtri-gramと呼ばれています。
文章の特徴量
文章を単語、N-gramに分解することができましたが、このままでは機械学習のアルゴリズムに入力することはできません。なぜなら、ニューラルネットワークなどの機械学習アルゴリズムは、入力は数値ベクトルを前提としているからです。データを、機械学習のアルゴリズムに入力可能なベクトルに変換することを特徴抽出と呼びます。以下は、代表的な文章の特徴抽出技術です。


演習1
以下の3つの文章が学習データとして与えられたとします。
"This is an apple"
"This is a banana"
"This is an orange"次の文章sの各単語の特徴量を求めてみましょう。
s="This is an orange."1)各単語のTF値:TF("This",s), TF("is",s), TF("an",s), TF("orange",s)を計算してください。
2)各単語のIDF値:IDF("This"), IDF("is"), IDF("an"), IDF("orange")を計算してください。※IDFを計算する際のlogは、自然対数(底がe)を使ってください。
3)各単語のTFIDF特徴量:TFIDF("This",s), TFIDF("is",s), TFIDF("an",s), TFIDF("orange",s)を計算してください。1)~3)の計算結果を、Moodleにて提出してください。