参考書
本ブログの内容の詳細は、「機械学習スタートアップシリーズ ゼロからつくるPython機械学習プログラミング入門」に掲載されています。
機械学習に必要な数学の復習から、機械学習のアルゴリズムの導出およびPythonの基本ライブラリのみを用いた実装方法まで学びたい方は、本書籍をご活用ください。
bookclub.kodansha.co.jp
Q学習の実行
演習3
これまでに実装した、discretizeState、updateQおよびselectActionをメインから呼び出し、Q学習を完成させましょう。
Qテーブルを更新するのには時間がかかるので、以下のようにエピソードの反復回数を20001回に変更してください。# 2) エピソード(試行)のループ for episode in np.arange(20001):以下のように、最初は谷底でうろうろしていた車が、徐々に左右に動けるようになり、最後にはスムーズに登れるようになっていくのを確認しましょう。
Training process of Mountain Car by Q-learning
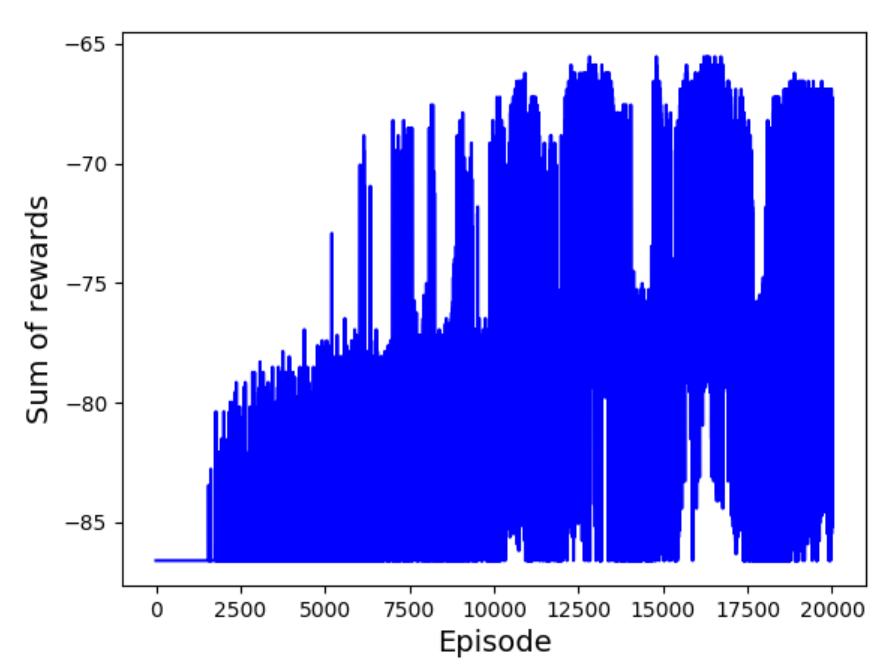
また、割引報酬和の推移を確認するために、各エピソードの割引報酬和を記録しているagent.sumRewardsを、以下のようにプロットするメソッドplotSumRewardsを追加してください。
エピソードの反復が進むにつれて、割引報酬和が上昇しているのがわかります。
宿題1
学習したQテーブルagent.Qを、pickleファイルに保存するagent.saveQ()と読み込むagent.loadQ()を追加しましょう。
pickleファイルの読み書きは、以下のようにdumpとloadを用います。【書き込み】
import pickle x = [] y = [] with open('example.pkl', 'wb') as fp: pickle.dump(x, fp) pickle.dump(y, fp)【読み込み】
import pickle with open('example.pkl', 'rb') as fp: x=pickle.load(fp) y=pickle.load(fp)次に、メインにて、学習したQテーブルを保存するコードと、以下のように保存したQテーブルを読み込みMountainCarの動作をデモンストレーションするコードを作成しましょう。
Example of Mountain Car trained by Q learning
宿題2
学習したQテーブルの各状態における最大値np.max(agent.Q,axis=2)を、以下のようにヒートマップを用いて可視化するメソッドagent.showQ(self)を追加しましょう。
可視化したQテーブルを観察し、どのようなQテーブルが学習されたのかについて考察してください。
ヒートマップの描画には、seabornのheatmapを用いましょう。以下は、seabornを用いてランダムに生成した数値のヒートマップを描画するスクリプトの例です。
def showQ(self): import seaborn as sns x = np.random.rand(50,50) # ヒートマップの描画 sns.heatmap(x) #------------------------------------
