データ解析を題材に、Pythonを用いた機械学習アルゴリズムの実装の演習を行います。本演習では、最近の機械学習ライブラリの普及によりブラックボックス化され、かえって理解が困難になった機械学習アルゴリズムの基礎的な部分の理解を深めることを目的としています。具体的には、scikit-learn、tensorflow, pytorch, kerasなどの機械学習のライブラリを使わずに、教師あり学習のニューラルネットワークおよび強化学習のQ学習を、pythonの基本ライブラリのみを用いてイチから実装します。
参考書
本ブログの内容の詳細は、「機械学習スタートアップシリーズ ゼロからつくるPython機械学習プログラミング入門」に掲載されています。
機械学習に必要な数学の復習から、機械学習のアルゴリズムの導出およびPythonの基本ライブラリのみを用いた実装方法まで学びたい方は、本書籍をご活用ください。
bookclub.kodansha.co.jp
1~2回目(Pythonの基礎):Pythonの環境の構築、numpyによる数値演算、matplotlib、pdbデバッグ、データ構造(リスト、タプル、辞書、numpy.ndarray、pandas.dataframe)、リスト内包表記、関数およびオブジェクト指向などPythonスクリプトの基礎的な記述方法を学びます。
2~3回目(ロジスティック回帰の実装):人工知能(3セメ)で学んだニューラルネットワークの復習し、ソフトマックス、交差エントロピー、最急降下法などを組み合わせて、2階層のニューラルネットワーク(ロジスティック回帰)を実装することにより、教師あり学習の基本的な実装方法を学びます。
3~4回目(ニューラルネットワークの実装):3階層のニューラルネットワークを学習するための勾配の導出とバックプロパゲーションの実装を通し、非線形なモデルの実装方法を学びます。
4~5回目(ニューラルネットワークの応用):Amazonの商品レビューの感情分類およびMNISTの手書き文字画像の分類を参考に、各グループでニューラルネットワークを応用する課題を選択し、ニューラルネットワークを応用する実践方法を学びます。
6回目(強化学習の基礎):強化学習の基礎(教師あり学習との違い、動物の行動学習、定式化)および実用的なQ学習法について学びます。また、ベンチマークツールのopen AI Gymのセットアップを行います。
7回目(Q学習の実装):Q学習法の実装を通し、強化学習の基本的な実装方法を学びます。また、Mountain Carタスクを用いて、実装したQ学習による強化学習の実験を行います。
8回目(強化学習の応用):Mountain Carタスクを参考に、各グループで強化学習を応用する課題を選択し、強化学習を応用する実践方法を学びます。
9回目(グループ発表):各グループごとに、選択した応用課題の概要、応用した結果、工夫したところ、および難しかったところを発表してもらい全体で共有します。
【Pythonによる機械学習(Pythonの基礎 1/4)の目次】
- 参考書
- Pythonとは
- Anacondaを用いたPython環境の構築
- 開発環境の構築
- jupyter notebookを用いたインタラクティブ開発
- Google colaboratoryを用いたインタラクティブ開発
- 変数と標準出力
- データ構造
- 演習1
Pythonとは
Pythonは、近年、機械学習を用いたデータ解析やソフトウェアの研究開発にて、標準的に利用されているスクリプト言語で、以下の利点を持っています。
- コンパイルを必要とせずインタラクティブに動作確認をしながら容易に実装ができる。
- ブロック構造にカッコを用いず、インデント(スペースやタブ)を用いるため可読性が高い。
- ライブラリが豊富なため、やりたいことが大抵はできる。
例)機械学習:scikit-learn,、数値演算:numpy、データ構造:pandas、ディープラーニングcaffe, tensorflow, chainer、画像処理cv2、グラフmatplotlib
- オブジェクト指向に対応しているので、大規模な実装にも対応している
- Cythonを用いてPythonスクリプトを、C言語に変換することにより高速化できる
- Windows、Linux、MacOSなど様々なOSで同じコードを実行できる(クロスプラットフォーム性)。
- オープンソースなため誰でも利用できるため、ユーザが多く、資料が豊富にある
Anacondaを用いたPython環境の構築
まず、各自、Pythonの環境を構築します。以下の手順で、最新版のPythonをインストールしてください。
1) 以下からPython3.xをダウンロードします。
https://www.anaconda.com/download/
赤枠の「Download」をクリックするとOSの一覧が表示されます。
利用しているOSに対応するインストーラをクリックしてダウンロードしてください。

2) ダウンロードしたexeファイルを実行して、Anacondaをインストールします。
以下のインストーラのガイドに従いインストールしてください。
「Next」をクリックします。
「I Agree」をクリックします。
「Next」をクリックします。

インストール先のフォルダを選択し、「Next」をクリックします。
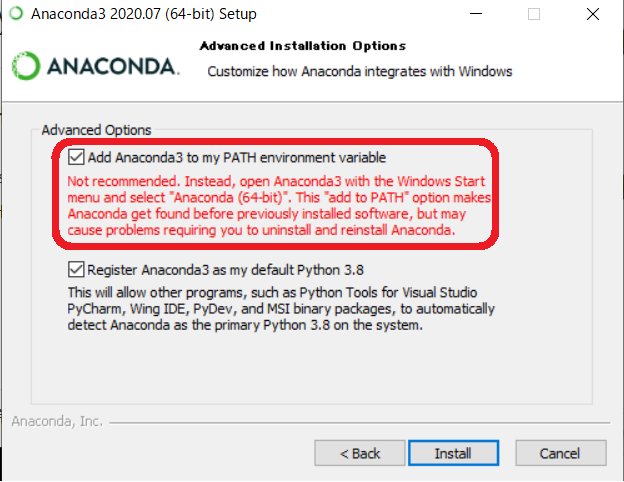
「Add Anaconda3 to my PATH environment variable」をチェックし、「Install」をクリックします。
3) pythonを実行する
まず、powershell(コマンドプロンプト)を起動します。

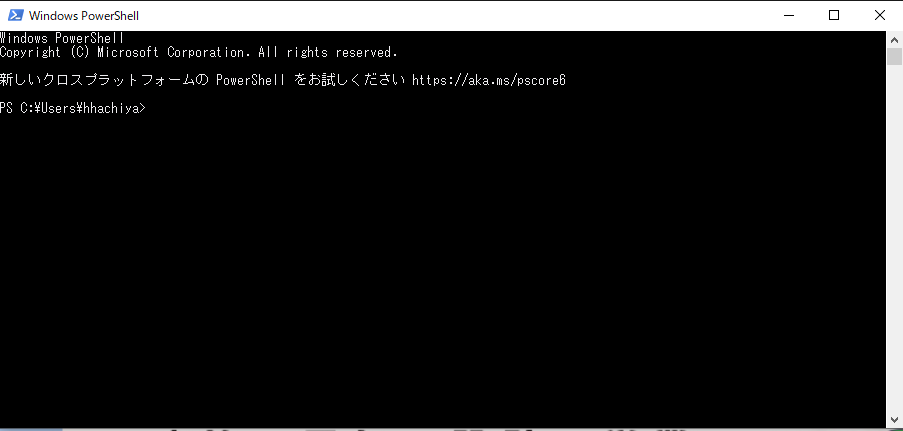
そして、pythonをインタラクティブモードで起動します。
> Python 3.6.3 |Anaconda, Inc.| (default, Oct 13 2017, 12:02:49) [GCC 7.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
1行目のバージョン情報に、「Python 3.6.3 |Anaconda, Inc.| 」のように表示されていることを確認しましょう。
開発環境の構築
本演習で用いるコードやデータは、gitでバージョン管理しています。リモートレポジトリは、以下のgithub上にリモートレポジトリ「intelligentSystemTraining」を作成しています。
https://github.com/hhachiya/intelligentSystemTraining
以下の手順で、開発環境(ローカルレポジトリ)を構築してください。
1) Webブラウザで「https://github.com/hhachiya/intelligentSystemTraining」をアクセスする
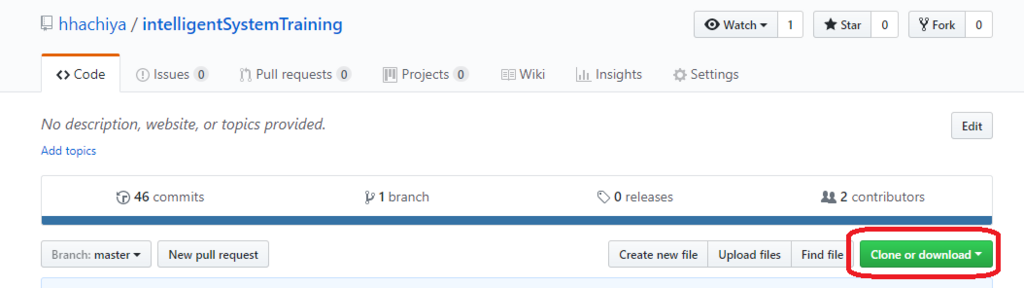
2) 「Clone or download」をクリックし、URLをコピーする
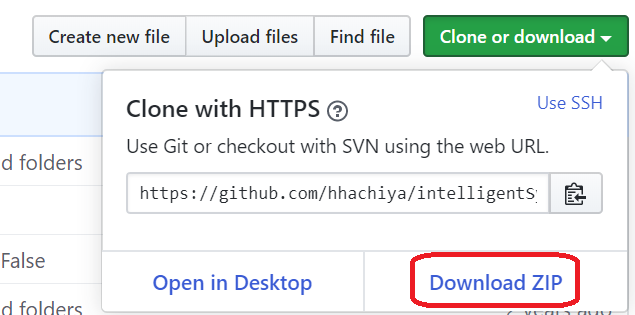
3)「Download ZIP」をクリックしてzipファイルをダウンロードする
4)ダウンロードしたzipファイルを自身の作業フォルダに解凍する
以下のようにintelligentSystemTraining-masterというフォルダが作成されていることを確認してください。
> ls intelligentSystemTraining-master/ README.md logisticRegression_template.py visualization classifier_template.py neuralNetwork_template.py data.py sentiment_labelled_sentences
本演習におけるコードの作成・実行などの作業は、上記の「intelligentSystemTraining-master」フォルダにて行ってください。
jupyter notebookを用いたインタラクティブ開発
jupyter notebookを用いると、ブラウザー上で実行結果を可視化しながら、pythonコードの開発を進めることができます。
「intelligentSystemTraining-master」フォルダにて、powershellを起動(シフト押しながら右クリックし、「PowerShellウィンドウをここで開く」を選択)します。
jupyter notebookは、以下のようにシェル(コマンドプロンプト)上でコマンドを打ち起動します。
> jupyter notebook
以下のように、ブラウザー(IE)が「localhost:8888/tree」にアクセスした状態で起動します。jupyter notebookが起動されたフォルダのファイルの一覧が表示されています。
次に、「New」ボタンをクリックし、「Python 3」を選択します。
そうすると、以下のような画面が表示されます。
「In []: 」の横にあるフォームにpythonのコードを入力し、Shift+Enterを押して実行します。

Google colaboratoryを用いたインタラクティブ開発
どうしてもパソコンにAnacondaをインストールするのが困難な場合は、
以下のGoogle colaboratoryを用いると、jupyter notebookと類似の環境を、特にAnacondaのセットアップなしでクラウド上に構築することができます
https://colab.research.google.com
Google colaboratoryを利用するためには、Googleのアカウントが必要になります。Googleアカウントを持っていない人は作成し、Google colaboratoryにアクセスすると以下のような画面が表示されます。
そして、下のほうにある「PYTHON3の新しいノートブック」をクリックします。
そうすると、jupyter notebookと似ていてGoogle流に拡張された画面が表示されます。
あとは基本的に、jupyter notebookと使い方は同じです。ただファイル読み書きに関しては、google driveを用いる点が大きくことなります。Google colaboratoryからgoogle driveのファイルを読み込む方法は以下のサイトを参考にしてください。
hirotaka-hachiya.hatenablog.com
変数と標準出力
Pythonでは,型宣言をせずに任意の名前の変数に値を代入することができます.代入された値に基づき,Python側で自動的に変数の型を決めます.
num = 10 string = "Hello world"
また,標準出力は,print関数を用います.以下のようにf文字列(f-strings)を用いて簡単に変数の値や数式の結果を文字列の中に挿入することができます.
具体的には、文字列の前にfを置き(f"xxx")、文字列中の中かっこのなかに変数や数式を置きます。
print(f"文字列{変数、計算式}文字列")
それでは,変数を設定し,print関数を用いて変数の値と型を標準出力してみましょう.以下のコードをjupyter notebookのフォームにコピーペーストして,Ctrl+Eneterで実行してみましょう.
num = 10 string = "Hello world" print(f"num={num}, type(num)={type(num)}") print(f"string={string}, type(string)={type(string)}")
実行結果は以下のようになります.変数numはint型,変数stringはstr型に設定されていることがわかります.
num=10, type(num)=<class 'int'> string=Hello world, type(string)=<class 'str'>
Jupyter notebookの画面上では以下のようになります.

データ構造
次にPythonの代表的なデータ構造について解説します。
Pythonには,多次元配列データを格納するためのデータ構造がいくつかあります。
リスト(Python 標準)
各要素をオブジェクト(数値、文字列、リスト自身など)として格納する変数。型を気にせず配列操作が簡単にできます。
以下のように、角括弧[オブジェクト1, オブジェクト2...]を用いて定義します。jupyter notebookのフォームに入力しCtrl+Eneterで実行してみましょう。
price = [120,180,300,150] fruit =["apple", "orange","pineapple","banana"] all = [price, fruit] all
[[120,180,300,150], ['apple', 'orange','pineapple','banana']]
リストの大きさ
len関数を用いると、以下のようにリストの大きさを求めることができます。
len(price)
4
要素へのアクセス
リストの要素にアクセスするためには、以下のように角括弧で要素のインデックスを指定します。要素のインデックスは、0から始まります。
print(price[0]) print(all[1]) print(all[1][1])
120 ['apple', 'orange', 'pinnaple', 'banana'] orange
numpy.ndarray
各要素を統一の型(float32, int, u32など)で格納する変数。厳密に型を意識して、行列やベクトルとして演算ができます。
以下のように、numpyライブラリをnpとしてインポートして、np.array(リスト)関数を用いて定義します。
import numpy as np price = np.array([120,180,300,150]) fruit = np.array(["apple", "orange","pineapple","banana"]) all = np.array([price, fruit])
numpyで自動的に選択された型を、dtypeを用いて表示します。
print(price.dtype) print(fruit.dtype) print(all.dtype)
int32 <U9 <U11
numpy.ndarrayの大きさ
shapeを用いると、以下のようにnumpy.ndarraryの形および大きさを求めることができます。
all.shape
(2, 4)
allは2行4列の配列になっているのがわかります.
スライス
numpy.ndarrayでは、スライスと呼ばれる操作で、 部分的に要素を抜き出すことができます。
price[0] % 最初(0番目)の要素 120 price[-1] % 最後の要素 150 price[1:3] % 1番目から2番目までの要素 [180, 300] price[:2] % 最初(0番目)から1番目までの要素 [120, 180]
数値演算
numpyのsum、mean、varおよびstd関数を用いると、和、平均、分散および標準偏差の計算ができます。
print(f"和={np.sum(price)}") print(f"平均={np.mean(price)}") print(f"分散={np.var(price)}") print(f"標準偏差={np.std(price)}")
和=750 平均=187.5 分散=4668.75 標準偏差=68.32825184358224
なお、print関数では、以下のようにf文字列(f-strings)を用いて簡単に変数の値や数式の結果を文字列の中に挿入することができます。
具体的には、文字列の前にfを置き(f"xxx")、文字列中の中かっこのなかに変数や数式を置きます。
print(f"文字列{変数、計算式}文字列")
pandas.dataframe
データベース(またはエクセル)のテーブルのように、カラム名(列)とインデックスを割り振って各要素を格納する変数。エクセル(csv形式)のデータの読み書きが簡単にできるため、データ解析でよく使われます。
以下のように、pandasライブラリをpdとしてインポートして、Series(numpy.ndarray, name="カラム名")を用いて定義します。
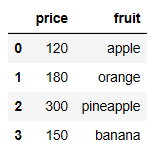
import pandas as pd price = pd.Series(np.array([120,180,300,150]),name="price") fruit = pd.Series(np.array(["apple","orange","pineapple","banana"]),name="fruit") df = pd.concat([price,fruit],axis=1) print(df)
これは、エクセルでは以下のような表を作っていることに対応します。
dataFrameからnumpy.ndarrayへの変換
valuesを用いることにより、dataFrameのテーブルをnumpy.ndarrayに変換することができます。
df.values
array([[120, 'apple'], [180, 'orange'], [300, 'pineapple'], [150, 'banana']], dtype=object
以下、リスト、numpy.ndarrayおよびdataframeを使ったサンプルコードです(※コードが表示されない方は、こちらを参照してください)。
上記のスクリプトをファイルlist_numpy_dataframe.pyに、文字コードをUTF-8で保存し以下のように実行します。
- コマンドプロンプト上で実行する場合
> python list_numpy_dataframe.py
- jupyter notebook上で実行する場合
![]()
要素の追加前: ['Yamada Taro' 'Yamada Hanako'] [ 172.5 160.5] 要素の追加後: ['Yamada Taro' 'Yamada Hanako' 'Wakayama Dai'] [ 172.5 160.5 180.2] ------- 全ての要素: ['Yamada Taro' 'Yamada Hanako' 'Wakayama Dai'] 0番目の要素: Yamada Taro 1番目までの要素: ['Yamada Taro' 'Yamada Hanako'] 最後の要素: Wakayama Dai 0から1番目までの要素: ['Yamada Taro' 'Yamada Hanako'] 170以上のインデックス: (array([0, 2], dtype=int64),) 170以上の要素: ['Yamada Taro' 'Wakayama Dai'] ------- d_dataframe: name height 0 Yamada Taro 172.5 1 Yamada Hanako 160.5 2 Wakayama Dai 180.2 name列: 0 Yamada Taro 1 Yamada Hanako 2 Wakayama Dai Name: name, dtype: object height列のインデックス0番: 172.
リストから、numpy.ndarrayに変換する際に、少数の場合はfloat64、文字列の場合はUnicode(U13, U6)に自動的に設定されていることがわかります。
また、numpy.ndarray(およびlist)では、appendを用いて簡単に要素を追加でき、さらに様々な要素への参照方法があることがわかります。
numpy.appendの詳細は、下記を参照してください。
https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.append.html
さらに、d_dataframeは、「name」または「height」のキーと、インデックスで各要素を参照できることがわかります。
演習1
d_dataframeに、年齢「age」の列を追加してみましょう。
以下のように、Yamada Taroさんは21歳、Yamada Hanakoさんは19歳、Wakayama Daiさんは30歳に設定してください。d_dataframe: name height age 0 Yamada Taro 172.5 21 1 Yamada Hanako 160.5 19 3 Wakayama Dai 180.2 30作成したスクリプトおよび出力結果を、Moodleにて提出してください。