<< scikit-learnを用いた機械学習(教師あり学習 2/3)
教師あり学習:分類
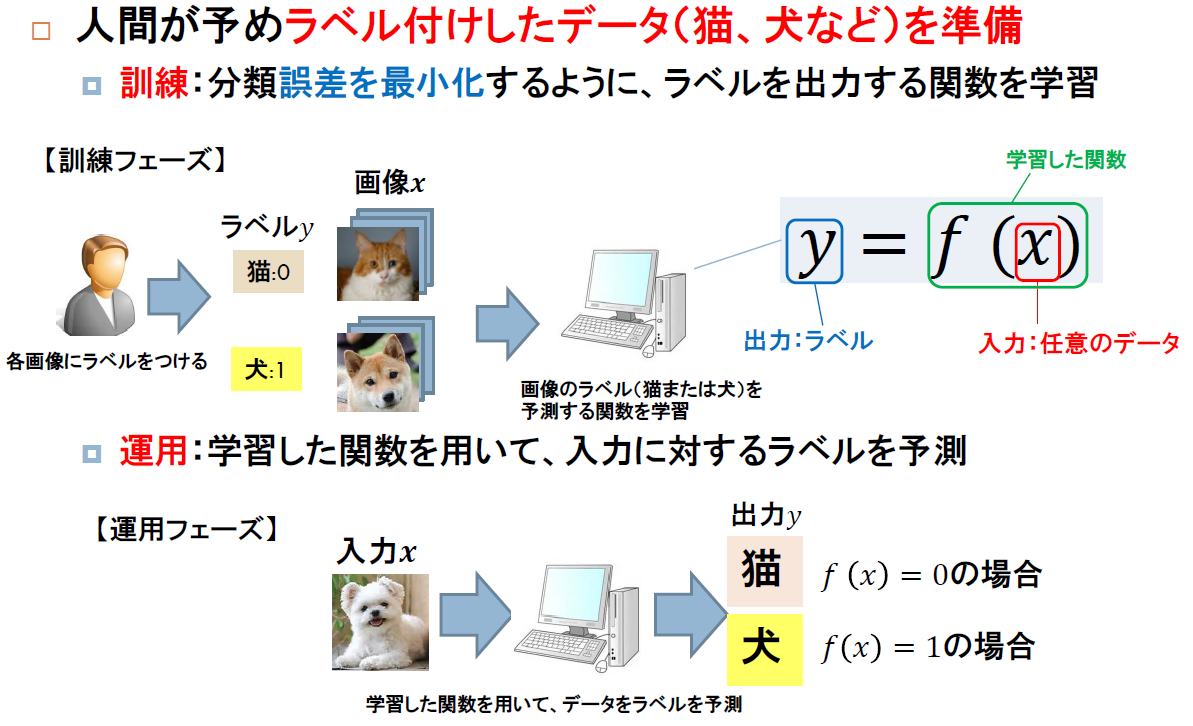
分類は、以下のように、入力のラベル
を出力として予測する問題です。
出力がラベルを表すや
に変わるだけで、基本的な処理フローは、回帰と同じです。
 gyazo.com
gyazo.com
手書き数字データMNIST
分類の題材として、手書き数字画像のMNISTを用います。MNISTにおける課題は、以下のような手書き数字の画像各々の0~9までの10種類ラベルを予測することです。

今回は、scikit-learnにて用意されている、動作確認用のdatasetsライブラリを用いて8x8の解像度に圧縮された1797枚の画像と、ラベルを、それぞれ入力と
として読み込みます。
from sklearn import datasets MNIST = datasets.load_digits() # MNISTデータの読み込み X=MNIST.data #入力画像 y=MNIST.target # 出力ラベル print(X.shape) print(y.shape)
(1797, 64) (1797,)
入力は、1797x64の行列になっていて、各行に1枚の8x8の解像度の画像が8x8=64次元のベクトルとして格納されています。0行目の画像を表示するために、numpyのreshapeを用いて8x8の行列に変形します。そして、以下のようにmatplotlib.pylabのimshowを用いて画像として表示します。
plt.imshow(np.reshape(X[0], [8,8]),cmap="gray") # 8x8に変形した画像の表示 plt.show()
ここで、cmap="gray"では、カラーマップをグレースケールに設定しています。

いわば、解像度8x8の画像をベクトルに変換することが、ここでは、(最も単純な)特徴ベクトルの抽出に対応しています。

関数の学習
回帰では、scikit-learnの線形回帰LinearRegressionクラスを用いましたが、ここでは、分類に特化したロジスティック回帰logisticRegressionを用います。ロジスティック回帰では、以下のようなシグモイド関数の傾きwと平行移動bを決めるパラメータを学習します。

以下は、logisticRegressionを用いて関数fを定義した後、fitメソッドを用いて訓練用データに対する予測誤差を最小化するように関数fのパラメータを学習します。
from sklearn.linear_model import LogisticRegression # 訓練用と評価用に分割 Xtr, Xte, ytr, yte = train_test_split(X,y,train_size=0.8,test_size=0.2) # ロジスティック回帰の学習 f = LogisticRegression() # 関数fの定義 f.fit(Xtr,ytr) # 関数fの学習
評価
分類の評価指標としては、よくprecision(適合率)、recall(再現率)、F1スコア(precisionとrecallの調和平均)、confusion matrix(混同分布)などが用いられます。
precision(適合率)
適合率は、関数fが予測したラベルのうち、正しく予測できたラベルの割合を表します。
recall(再現率)
再現率は、真のラベルのうち、関数fが正しく予測できたラベルの割合を表します。
F1スコア(適合率と再現率の調和平均)
適合率と再現率とが、どれくらいバランスよく高い値をとっているかを表します

confusion matrix (混同行列)
以下のように、各ラベルを正しく予測できた数、どのラベルにどれくらい間違ったかを表す行列です。

Pythonには、これらの評価指標を計算してくれる非常に便利ライブラリmetricsがあります。
以下は、confusion
from sklearn import metrics ypre = f.predict(Xte) print(metrics.confusion_matrix(yte, ypre)) # confusion matrix print(metrics.classification_report(yte, ypre)) # precision, recall, F1 score
[[39 0 0 0 0 0 0 0 0 0] [ 0 35 0 2 0 0 0 0 2 0] [ 0 0 35 1 0 0 0 0 0 0] [ 0 0 0 33 0 1 0 1 0 0] [ 0 0 0 0 37 0 1 0 0 1] [ 0 1 0 0 0 26 0 0 0 0] [ 0 0 0 0 0 0 36 0 0 0] [ 0 0 0 0 0 0 0 39 0 0] [ 0 1 0 0 0 1 0 0 28 1] [ 0 1 0 0 0 1 0 0 3 34]] precision recall f1-score support 0 1.00 1.00 1.00 39 1 0.92 0.90 0.91 39 2 1.00 0.97 0.99 36 3 0.92 0.94 0.93 35 4 1.00 0.95 0.97 39 5 0.90 0.96 0.93 27 6 0.97 1.00 0.99 36 7 0.97 1.00 0.99 39 8 0.85 0.90 0.88 31 9 0.94 0.87 0.91 39 avg / total 0.95 0.95 0.95 360
教師あり学習のフローのクラス化

以下は、教師あり学習(分類)の一連のフローを、クラス化したものです。
# -*- coding: utf-8 -*- import pandas as pd import numpy as np import matplotlib.pylab as plt from sklearn import linear_model from sklearn.model_selection import train_test_split from sklearn import datasets from sklearn import metrics class Classification: #--------------- # コンストラクタ # dataType:データの種類(文字列で指定、例:'MNIST') def __init__(self, dataType='MNIST'): if dataType == 'MNIST': self.data = datasets.load_digits() # MNISTデータの読み込み # 予測のフラグ self.isPred = False # 標準化のフラグ self.isNormalize = False #--------------- #--------------- # 分類用のデータを作成するメソッド def createClassData(self): self.X = self.data.data # 訓練用データ self.y = self.data.target # 評価用データ #--------------- #--------------- # 標準化するメソッド def normalize(self): self.isNormalize = True # 標準化のフラグオン self.Xmean = np.mean(self.X,axis=0) # 平均 self.Xstd = np.std(self.X,axis=0) # 標準偏差 self.X = (self.X-self.Xmean)/self.Xstd # 標準化 #--------------- #--------------- # 訓練用と評価用とに分割するメソッド # trRatio:学習データの割合((0,1]の少数で指定、例:0.8) def split2TrainTest(self,trRatio=0.8): self.Xtr, self.Xte, self.ytr, self.yte = \ train_test_split(self.X,self.y,train_size=trRatio,test_size=1-trRatio) # 訓練用と評価用とに分割 #--------------- #--------------- # 分類用の関数を学習するメソッド def trainClassification(self): self.f = linear_model.LogisticRegression() # 関数fの定義 self.f.fit(self.Xtr, self.ytr) # 関数fの学習 #--------------- #--------------- # 予測メソッド def predict(self): self.isPred = True # 予測フラグをオン self.ypre = self.f.predict(self.Xte) # 予測 #--------------- #--------------- # 分類の評価 def evalClassification(self): # 予測 if not self.isPred: self.predict() # confusion matrix print("confusion matrix=\n",metrics.confusion_matrix(self.yte, self.ypre)) # precision, recalll, f1score print(metrics.classification_report(self.yte, self.ypre)) #--------------- #--------------- # 予測結果の画像を表示するメソッド # nrow:行数(int型、例:2) # ncols:列数(int型、例:5) # imgs:画像(numpy array型、画像数x画像高さx画像幅) # trueLabels:真のラベル(numpy array型、1x画像数) # predLabels:予測のラベル(numpy array型、1x画像数) def showImg(self,nrow, ncol, imgs, trueLabels, predLabels): fig = plt.figure() # 画像の表示 for ind in range(np.min([len(imgs),nrow*ncol])): ax=fig.add_subplot(nrow,ncol,ind+1) ax.imshow(np.reshape(imgs[ind],[8,8]), cmap='gray') ax.set_title(f"{trueLabels[ind]}({predLabels[ind]})") plt.tight_layout() plt.show() #--------------- myData = Classification() # Classificationクラスのインスタンス化 myData.createClassData() # 教師ありデータの作成 myData.split2TrainTest() # 訓練用と評価用とに分割 myData.normalize() # 標準化 myData.trainClassification() # 分類関数の学習 myData.evalClassification() # 分類関数の評価
演習2
showImgメソッドを用いて、以下のように分類に失敗した画像を表示するコードをメインに追加しましょう。
