<< Pythonによる機械学習2(ロジスティック回帰 2/4)
【Pythonによる機械学習2(ロジスティック回帰 3/4)の目次】
ロジスティック回帰のテンプレート
人工データの準備が整ったので、次はロジスティック回帰の実装に入りたいと思います。いちから全て実装するのは難しいので、intelligentSystemTrainingにある、人工データを用いてロジスティックモデルを学習および評価するPythonスクリプトのテンプレートclassifier_template.pyおよびlogisticRegression_template.pyを用います。
logisticRegressionクラスには、以下のメソッドが定義されています。
1)__init__: コンストラクタ、ロジスティックモデルのパラメータWとbを正規分布(numpy.random.normal)を用いて初期化
2)softmax: ソフトマックス関数
3)update: 最急降下法によるモデルパラメータの更新※未実装
4)loss: 交差エントロピー損失の計算※未実装
5)predict: 事後確率の計算
class logisticRegression(classifier.basic): #------------------------------------ # 1) 学習データおよびモデルパラメータの初期化 # x: 学習入力データ(入力ベクトルの次元数×データ数のnumpy.array) # t: one-hot学習カテゴリデータ(カテゴリ数×データ数のnumpy.array) # batchSize: 学習データのバッチサイズ(スカラー、0の場合は学習データサイズにセット) def __init__(self, x, t, batchSize=0): # デフォルト初期化 self.init(x,t,batchSize) # モデルパラメータをランダムに初期化 xDim = x.shape[0] tDim = t.shape[0] self.W = np.random.normal(0.0, pow(xDim, -0.5), (xDim, tDim)) self.b = np.random.normal(0.0, pow(tDim, -0.5), (tDim, 1)) #------------------------------------ #------------------------------------ # 2) ソフトマックスの計算 # x: カテゴリ数×データ数のnumpy.array def softmax(self,x): # x-max(x):expのinfを回避するため e = np.exp(x-np.max(x)) return e/np.sum(e,axis=0) #------------------------------------ #------------------------------------ # 3) 最急降下法によるパラメータの更新 # alpha: 学習率(スカラー) # printEval: 評価値の表示指示(真偽値) def update(self, alpha=0.1,printEval=True): # 次のバッチ x, t = self.nextBatch(self.batchSize) # データ数 dNum = x.shape[1] # Wの更新 predict_minus_t = self.predict(x) - t self.W -= alpha * 0 # 【wの勾配の計算】 # bの更新 self.b -= alpha * 0 # 【bの勾配の計算】 # 交差エントロピーとAccuracyを標準出力 if printEval: # 交差エントロピーの記録 self.losses = np.append(self.losses, self.loss(self.x[:,self.validInd],self.t[:,self.validInd])) # 正解率エントロピーの記録 self.accuracies = np.append(self.accuracies, self.accuracy(self.x[:,self.validInd],self.t[:,self.validInd])) print("loss:{0:02.3f}, accuracy:{1:02.3f}".format(self.losses[-1],self.accuracies[-1])) #------------------------------------ #------------------------------------ # 4) 交差エントロピーの計算 # x: 入力データ(入力ベクトルの次元数×データ数のnumpy.array) # t: one-hot学習カテゴリデータ(カテゴリ数×データ数のnumpy.array) def loss(self, x,t): crossEntropy = 0 #【交差エントロピーの計算】 return crossEntropy #------------------------------------ #------------------------------------ # 5) 事後確率の計算 # x: 入力データ(入力ベクトルの次元数×データ数のnumpy.array) def predict(self, x): return self.softmax(np.matmul(self.W.T,x) + self.b) #------------------------------------
ここで、学習データと同様に、機械学習のアルゴリズムの実装では、モデルパラメータを、以下のような行列構造で表現ていることを確認しましょう。

メインでは、以下のようにフローなっています。
1)Data.artificialクラスをインスタンス(myData)化し、学習用・評価用データの生成
2)logisticRegressionクラスをインスタンス(classifier)化し、モデルの初期化
3)により、学習前の各カテゴリの事後確率を描画
4)classifier.update(alpha=learningRate)をNite回繰り返し、モデルパラメータを更新
5)反復の度に、学習率learning_rateをdecayRate倍し、更新幅を減衰
6)classifier.loss(myData.xTest,myData.tTest)により、評価データに対する損失を計算
7)最後に、myData.plotClassifier(classifier,"train")により、学習したモデルの事後確率を描画
if __name__ == "__main__": # 1)人工データの生成(簡単な場合) myData = data.artificial(300,150,mean1=[1,2],mean2=[-2,-1],mean3=[2,-2],cov=[[1,-0.8],[-0.8,1]]) # 1) 人工データの生成(難しい場合) #myData = data.artificial(300,150,mean1=[1,2],mean2=[-2,-1],mean3=[4,-2],mean3multi=[-2,4],cov=[[1,0],[0,1]]) # 2)ロジスティック回帰(2階層のニューラルネットワーク)モデルの作成 classifier = logisticRegression(myData.xTrain, myData.tTrain) # 3)学習前の事後確率と学習データの描画 myData.plotClassifier(classifier,"train",prefix="posterior_before") # 4)モデルの学習 Nite = 1000 # 更新回数 learningRate = 0.01 # 学習率 decayRate = 0.99 # 減衰率 for ite in np.arange(Nite): print("Training ite:{} ".format(ite+1),end='') classifier.update(alpha=learningRate) # 5)更新幅の減衰 learningRate *= decayRate # 6)評価 loss = classifier.loss(myData.xTest,myData.tTest) accuracy = classifier.accuracy(myData.xTest,myData.tTest) print("Test loss:{}, accuracy:{}".format(loss,accuracy)) # 7)学習した事後確率と学習データの描画 myData.plotClassifier(classifier,"train",prefix="posterior_after")
ロジスティック回帰のテンプレートの実行
以下のように、logisticRegression_template.pyを実行します。
> python logisticRegression_template.py Training ite:1 loss:0.000, accuracy:0.000 Training ite:2 loss:0.000, accuracy:0.000 Training ite:3 loss:0.000, accuracy:0.000 Training ite:4 loss:0.000, accuracy:0.000 Training ite:5 loss:0.000, accuracy:0.000 ...
実行後、スクリプトと同じフォルダに、以下のように学習前と学習後の各カテゴリの事後確率の画像が保存されます。
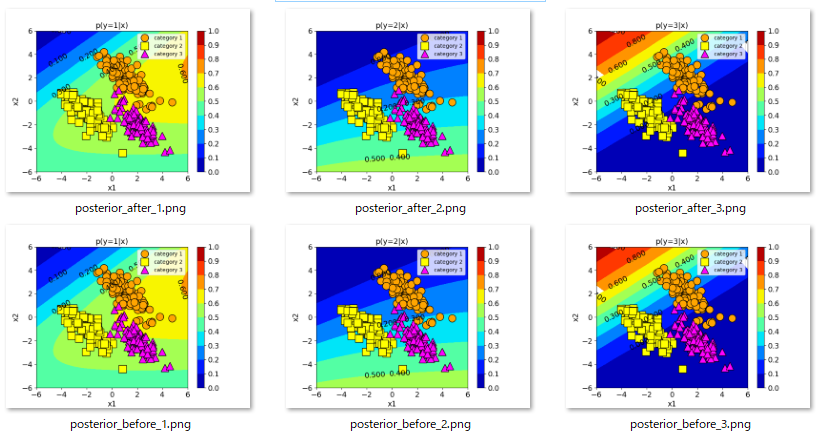
当然ながらランダムに設定されたモデルパラメータでは、カテゴリを分類できるような事後確率が獲得できていないのがわかります。また、現在は最急降下法のupdateメソッドが記載されていないので、学習後の事後確率は学習前と同じになっているのもわかります。
ロジスティック回帰のテンプレートには、まだ未実装の最急降下法(updateメソッド)と交差エントロピー(lossメソッド)があります。
演習3
演習1で導出したwとbの勾配を、以下のupdateメソッドの【wの勾配の計算】と【bの勾配の計算】の部分に実装し、最急降下法を完成させましょう。
#------------------------------------ # 2)最急降下法によるパラメータの更新 def update(self, alpha=0.1,printEval=True): # 次のバッチ x, t = self.nextBatch(self.batchSize) # データ数 dNum = x.shape[1] # Wの更新 predict_minus_t = self.predict(x) - t self.W -= alpha * 0 # 【wの勾配の計算】 # bの更新 self.b -= alpha * 0 # 【bの勾配の計算】 # 交差エントロピーとAccuracyを標準出力 if printEval: # 交差エントロピーの記録 self.losses = np.append(self.losses, self.loss(self.x[:,self.validInd],self.t[:,self.validInd])) # 正解率エントロピーの記録 self.accuracies = np.append(self.accuracies, self.accuracy(self.x[:,self.validInd],self.t[:,self.validInd])) print("loss:{0:02.3f}, accuracy:{1:02.3f}".format(self.losses[-1],self.accuracies[-1])) #------------------------------------ヒント1:Wの勾配を計算する際には、真値と予測値の差の行列predict_minus_t(3行300列)と、入力のの行列x(2行300列)の積を用いましょう。
ヒント2:bの勾配を計算する際には、和の記号に相当するnumpy.sum()を用いましょう。例えば、(3,300)の行列Xを列方向に和を取る場合は、np.sum(X, axis=1,keepdims=1)を用います。ここで、「keepdims=1」は行列の形を維持するためのオプションです。「keepdims=0」の場合、和の形は(3,)になるのに対し、「keepdims=1」の場合、和の形は(3,1)の列ベクトルとなります。