<< Pythonによる機械学習1(Pythonの基礎 4/4)
【Pythonによる機械学習1(Pythonの基礎 補足)の目次】
jupyter notebookを用いたインタラクティブ開発
jupyter notebookを用いると、ブラウザー上でグラフやdataframeの表を可視化しながら、pythonコードの開発を進めることができます。jupyter notebookは以下のように、シェル(コマンドプロンプト)上でコマンドを打ちます。
> jupyter notebook
以下のように、ブラウザー(IE)が「localhost:8888/tree」にアクセスした状態で起動します。jupyter notebookが起動されたフォルダのファイルの一覧が表示されています。
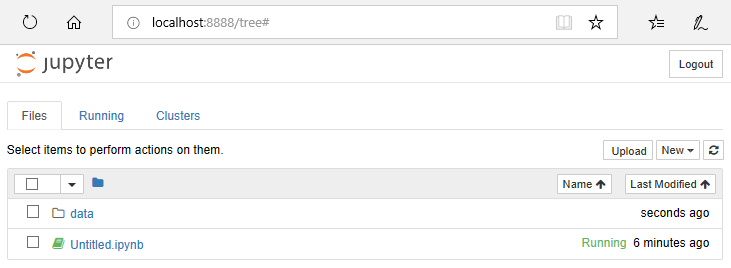
次に、「New」ボタンをクリックし、「Python 3」を選択します。
そうすると、以下のような画面が表示されます。
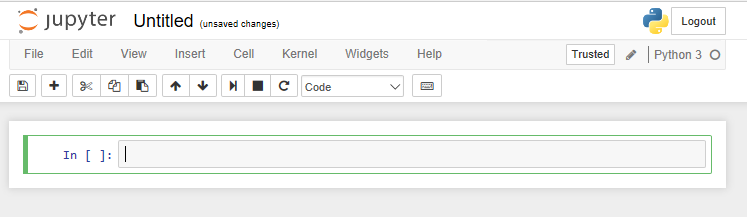
「In []: 」の横にあるフォームにpythonのコードを入力していきます。

上記のコードは、Kaggleにより公開されている「House Prices: Advanced Regression Techniques」からダウンロードしたデータの「train.csv」をdataframeとして読み込み、最初の10行を表示した例です。
streamlitを用いた開発
streamlitを用いると、ユーザから入力に応じて動的にpythonでグラフや表を表示するウェブアプリ作成することができます。また、sream.ioにアカウントを登録するとgithubと連携し、作成したアプリをデプロイし、インターネット上で公開することができます。
まず、pipを用いてstreamlitをインストールします。
> pip install streamlit
次に、streamlitを用いた以下のようなコードを作成します。
import streamlit as st import pandas as pd import plotly.express as px import numpy as np # 一様分布に従ってランダムサンプル x1 = np.random.rand(100) # 正規分布に従ってランダムサンプル x2 = np.random.randn(100) # dataframeの作成 size = len(x2) df = pd.DataFrame({"sample value":np.concatenate([x1,x2]), "type": ["uniform random"]*size+["normal random"]*size, "sample index": np.concatenate([np.arange(size),np.arange(size)])}) # 標準出力 st.write("dataframeの表示") df # 選択ボックス chart_type = st.selectbox('グラフの種類を選択してください', ['折れ線グラフ', '散布図']) if chart_type == '折れ線グラフ': fig = px.line(df,x="sample index", y="sample value", color="type") else: fig = px.scatter(df,x="sample index", y="sample value", color="type") st.plotly_chart(fig)
このコードをtest.pyに保存したとすると、以下のようにコマンドプロンプト上で、実行します。
> streamlit run test.py
そうすると、ブラウザー上に、以下のようなページが表示されます。

選択ボックスで、グラフを散布図に変更することができます。


stramlit.ioにアカウントを登録すると、ページの右上に以下のようにDeployボタンが表示されますので、これをクリックしてデプロイします。

そうすると、インターネット上でアプリを公開することができます。
dataframeを用いた簡単なデータ分析
dataframeのdesribe関数を用いると基本的な統計量を計算し表示します。また、meanやmedianなど統計量を直接指定して計算することもできます。以下の例では、カラム「SalePrice」に対してdescribe、meanおよびmedianを実行しています。

seabornを用いたデータの可視化
seabornはmatplotlibをベースにしたテンプレート型のグラフ描画ライブラリです。ここでテンプレートと言っているのは、予めグラフのデザインがあらかじめ見やすいように設定されているという意味dす。つまり、seabornライブラリを用いると、特に意識しなくても簡単にきれいで見やすいグラフを描画することができます。
seabornの詳細については、https://seaborn.pydata.org/を参照してください。
以下は、https://seaborn.pydata.org/generated/seaborn.distplot.htmlを用いたSalePriceの分布を、ヒストグラム、KDE(Kernel Density Estimation)およびrugでプロットした例です。

以下は、ガウス分布をfittingした例です。

以下は、横軸に「GrLivArea」と縦軸に「SalePrice」をとった場合の分布のヒートマップです。

以下は、「HouseStyle」の各カテゴリごとの、「SalePrice」の箱ひげ図の例です。

以下は、箱ひげ図を直感的にわかりやすくしたバイオリンプロットの例です。

以下は、SalePrice、GrLivArea、YearBuiltの各ペアの散布図(対角要素は、単独のヒストグラム)をプロットする例です。

house priceデータを用いた分析については、以下が参考になります。
Comprehensive data exploration with Python | Kaggle
以下は、作成したjupyter notebookのipynbファイルです。
gist05f18ab77db442bbc1ed80b7c160b0df