<< Pythonによる機械学習1(Pythonの基礎 3/4)
【Pythonによる機械学習1(Pythonの基礎 4/4)の目次】
matplotlib.pylabを用いたプロット
Pythonでは、グラフのプロットにmatplotlibライブラリが用いられます。
以下は、matplotlibを用いたグラフのプロットの例です。
上記のスクリプトをファイルplotSample.pyに保存し以下のように実行します。
> python plotSample.py
以下のようなグラフが表示されるとともに、ファイル「plotSample.png」に保存されます。

plotlyを用いたプロット
plotlyライブラリを用いると、拡大・縮小・クロップ・値の表示などインタラクティブな操作ができるグラフ作ることができます。
https://github.com/plotly/plotly.py
コマンドプロンプト上で、pipを用いてplotlyをインストールします。
> pip install plotly
plotlyは、データ構造としてpandas.dataFrameを前提にしていますので、上記のmatplotlibと同様のグラフを作るためには、まずdataframeを作ります。
import numpy as np import pandas as pd # 一様分布に従ってランダムサンプル x1 = np.random.rand(100) # 正規分布に従ってランダムサンプル x2 = np.random.randn(100) # dataframeの作成 size = len(x2) df = pd.DataFrame({"sample value":np.concatenate([x1,x2]), "type": ["uniform random"]*size+["normal random"]*size, "sample index": np.concatenate([np.arange(size),np.arange(size)])}) df
このdfは、以下のように、sample value, sample indexおよびtypeをカラムに持つ表データになっています。

そして、plotly.expressのline関数にdfを渡し、x軸、y軸に設定するカラム(sample indexとsample value)およびlegendに設定するカラム(type)を指定します。
import plotly.express as px fig = px.line(df,x="sample index", y="sample value", color="type") fig.show()
これにより、以下のようにマウスで拡大・縮小・クロップ・値の表示ができるインタラクティブなグラフを表示することができます。

同様に散布図も以下のように作ることができます。
import plotly.express as px fig = px.scatter(df,x="sample index", y="sample value", color="type") fig.show()

オブジェクト指向のPythonスクリプトの例
Pythonでは、関数とクラスの定義を以下のような形式で記述します。
def 関数名(引数1,引数2, ...): 関数の処理
class クラス名: def __init__(self, 引数1, 引数2, ….): #コンストラクタの定義 def メソッド名(self, 引数1, 引数2, ….): #メソッドの定義
ここで、self.xxxはインスタンス変数で、コンストラクタとメソッドの最初の引数はselfを記述しなければなりません。
以下は、文章データを扱うクラスの定義の例です。
上記のスクリプトをファイルsentenceData.pyに保存します。本スクリプトでは、sentiment_labelled_sentencesフォルダ下にあるAmazonの商品レビューデータ「amazon_cells_labelled.txt」を読み込みます。このファイルは、以下のように「sentence」列に商品レビューの文章、および「score」列にスコア(0または1)を格納しています。

そして、スクリプトを実行すると、以下のようにキーワード「very good」を含む商品レビューの文章を検索し表示します。
0 : The price was very good and with the free shipping and all it was a good purchase. 1 : I love my 350 headset.. My Jabra350 bluetooth headset is great, the reception is very good and the ear piece is a comfortable fit. 2 : very good product, well made. 3 : The design is very good.4. 4 : A lot of websites have been rating this a very good phone and so do I.
上記のスクリプトでは、以下の変数とメソッドを持つsentenceというクラスを定義しています。
- インスタンス変数self.datapath:データが置いてあるフォルダ名
- インスタンス変数self.data:読み込んだデータを格納するpandas.dataframe
- メソッドsearch(keyword):keywordで読み込んだデータの「sentence」列で、keywordの文字列を含んでいる文章を返す
また、pandas.Series.str.containsと、pandas.dataframe.valuesについては以下を参照してください。
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.str.contains.html
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.values.html
宿題2
1) スコアが「1」の商品レビューの文章を、numpy.arrayの各要素に格納して返すメソッドgetPositiveSentence()を、クラスsentenceに追加してみましょう。
ヒント:「score」列の値が「1」と等しいか否かの真偽値は、以下のようにして取得できます。> myData.data['score']==1 0 False 1 True 2 True 3 False 4 True 5 False 6 False 7 True 8 False 9 False ...
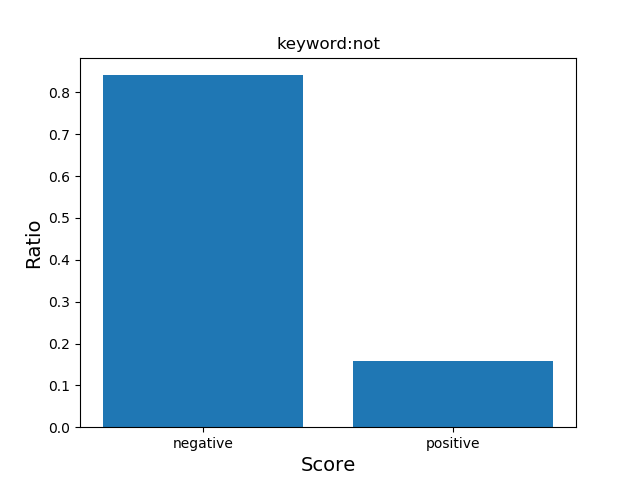
2) 任意のキーワードを含む商品レビューの文章を検索し、ヒットした文章のスコアが「1」と「0」の割合を計算し、以下のような棒グラフをプロットするメソッドplotScoreRatio(keyword)を、クラスsentenceに追加してみましょう。
ヒント:plotly.express.bar(dataframe, x='カラム名', y='カラム名')を用いると棒グラフをプロットできます。詳細は以下を参照してください。
https://plotly.com/python/bar-charts/ヒント:matplotlib.pyplot.bar(データx軸, データy軸, tick_label=ラベルデータ, align="center")を用いると棒グラフをプロットできます。詳細は以下を参照してください。
https://matplotlib.org/devdocs/api/_as_gen/matplotlib.pyplot.bar.html【キーワード「not」のスコアの割合】
plotly.express.bar:
matplotlib.pyplot.bar:
作成したスクリプトおよび出力結果を、次回までにMoodleにて提出してください。